

Table of Links
3 Model and 3.1 Associative memories
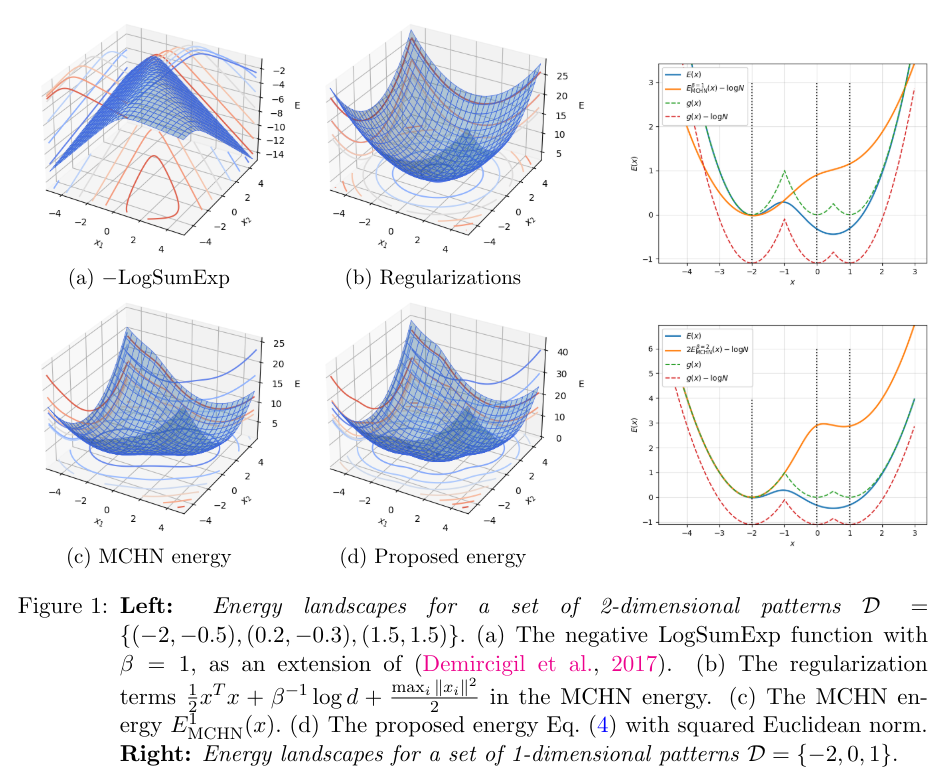
6 Empirical Results and 6.1 Empirical evaluation of the radius
6.3 Training Vanilla Transformers
7 Conclusion and Acknowledgments
Appendix B. Some Properties of the Energy Functions
Appendix C. Deferred Proofs from Section 5
Appendix D. Transformer Details: Using GPT-2 as an Example
3.2 Transformer blocks
Transformers (Vaswani et al., 2017) are made of a stack of homogeneous layers, where each consists of a multi-head attention sub-layer, a feed-forward sub-layer, an add-norm operation with a skip connection, and layer normalization. As an example of a typical Transformer, the GPT-2 architecture is discussed in Appendix D. The multi-head attention and feed-forward (FF) layers account for most of the parameters in the model.

Observation 2 The attention layer and the feed-forward layer can be conceptually integrated into a unified transformer layer.
The attention layers and the FF layers contribute to the majority of the model’s parameters, such that the number of parameters N is proportional to the square of the embedding dimension. The ratio depends on the number of layers and the hidden dimensions of the
transformer blocks. In the current work, we do not consider other modifications such as lateral connections, skip-layer connections, or other compressive modules such as (Xiong et al., 2023; Fei et al., 2023; Munkhdalai et al., 2024).
Authors:
(1) Xueyan Niu, Theory Laboratory, Central Research Institute, 2012 Laboratories, Huawei Technologies Co., Ltd.;
(2) Bo Bai baibo ([email protected]);
(3) Lei Deng ([email protected]);
(4) Wei Han ([email protected]).
This paper is